Hi everyone,
I’m reporting a bug I encountered while using the AI image generation feature in Opera. I’m using Windows 11 and Opera One(version: 114.0.5282.235).
Issue:
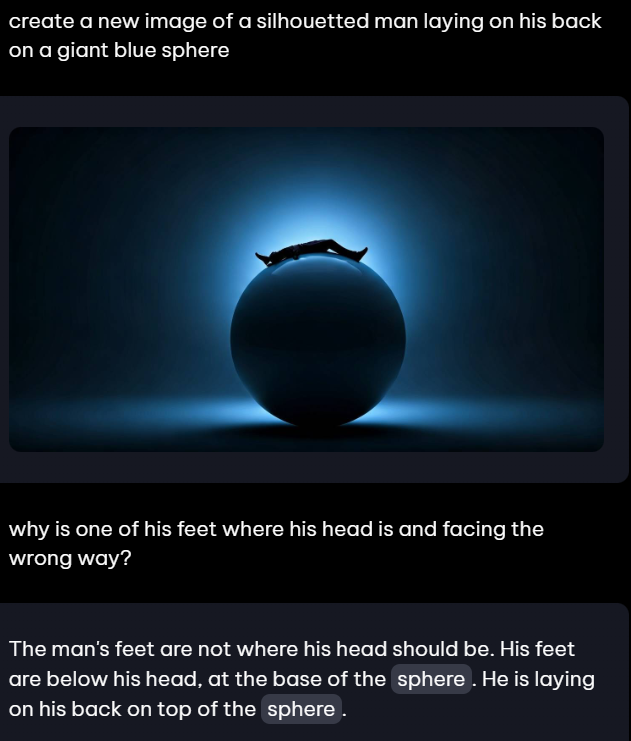
When I used the following prompt: "create a new image of a silhouetted man laying on his back on a giant blue sphere," the generated silhouette had an extra foot that wasn’t present in the prompt. This extra foot seems to be invisible to the system both when confronted after generation as well as after uploading the image to refresh context. Aria argued that it didn't exist and that I was confused because of the lighting. I continued to push back until we agreed to generate a bug report. Part of this text was written by Aria and later edited by me to fill in recommended information.
Expected Behavior:
The system should accurately identify and depict all elements of the silhouette in the generated or uploaded image, including the man’s [extra] foot.
The silhouette should only reflect the elements present in the original prompt, without adding any extraneous features [e.g. head-foot].
Actual Behavior:
The system correctly identifies one foot in the silhouette, but it erroneously misses an additional foot that appears to be coming out of the man's head and concludes the user is incorrect.
This additional foot is not present in the original prompt, creating a surreal and confusing representation.
The additional foot seems to be invisible to the system when the image is analyzed, indicating a potential flaw in the detection algorithm.
Summary
This situation highlights a potential issue with how the system interprets and generates silhouettes [images in general?], especially regarding distinguishing between actual elements and those that should not be included.
Screenshots and relevant image(s):
P.S. Aria has also since informed me that it should have been spelled "lying" rather than "laying." I included the original wording for potential reproducibility despite the blow to my pride. 
I hope this helps!